本系列文章部分內容由AI生成,最終有經過人工確認及潤稿。
在之前的學習中,我們深入探討了計算機視覺、深度學習、可解釋的人工智慧等主題。今天,我們將踏入人工智慧的一個重要領域:強化學習(Reinforcement Learning, RL)。強化學習模擬了生物學習的過程,讓智能體通過與環境的交互,學習如何採取行動以最大化累積的獎勵。強化學習在遊戲 AI、自主導航、機器人控制等領域具有廣泛的應用。讓我們一起深入了解強化學習的原理、方法和應用。
強化學習是一種機器學習方法,通過讓智能體(Agent)與環境(Environment)進行互動,學習最優的行動策略(Policy),以最大化累積獎勵(Reward)。
MDP 是強化學習的數學框架,包含以下元素:
尋找一個策略𝜋(𝑎∣𝑠),使得累積獎勵期望𝐺𝑡最大化: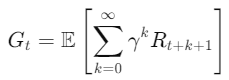
狀態價值函數(𝑉(𝑠))表示在狀態𝑠下,遵循策略𝜋所能獲得的累積獎勵期望。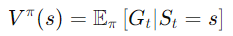
行動價值函數(𝑄(𝑠,𝑎))
表示在狀態𝑠下,採取行動𝑎,並遵循策略𝜋所能獲得的累積獎勵期望。
利用已知的環境模型,通過迭代更新價值函數,找到最優策略。
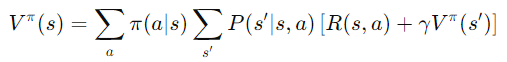
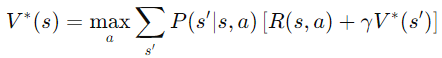
通過多次完整的遊戲過程,估計價值函數。
結合動態規劃和蒙特卡羅方法,利用當前估計更新價值函數。
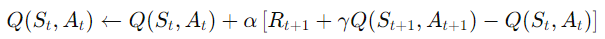
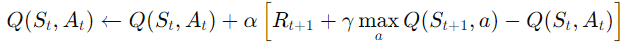
利用深度神經網絡近似價值函數或策略函數,處理高維連續狀態空間。
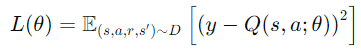
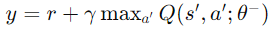
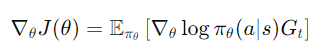
今天,我們深入學習了 強化學習 的基本概念、主要算法和應用案例。強化學習通過讓智能體與環境交互,學習最優策略,在人工智慧中扮演著重要角色。從 Q-Learning 到深度強化學習,我們見證了技術的發展和突破。同時,我們也了解了強化學習面臨的挑戰和未來的發展方向。希望通過今天的學習,您對強化學習有了更深入的理解,並能在未來的研究和工作中應用這些知識。
那我們就明天見了~掰掰~~


 iThome鐵人賽
iThome鐵人賽